
Dyslexia, also known as a reading disorder, is a condition in which a person displays reading difficulties. The underlying mechanisms of dyslexia are problems within the brain’s language processing. Dyslexia is the most common reading disability that affects 3–7% of the population, yet, even up to 20% may have some degree of Dyslexia symptoms.
Through the use of compensation strategies, therapy and educational support, dyslexic individuals can learn to read and write. There are techniques and technical aids which help to manage or mitigate disorder symptoms. You can find some evidence that the use of specially-tailored fonts may help to deal with dyslexia.
Around January of last year, we started talking with Omolab, a visual communications studio that gathers different experts and companies, with the goal of creating communication tools. One tool they created with the help of typographers is Omotype, a font designed to help those affected by dyslexia.

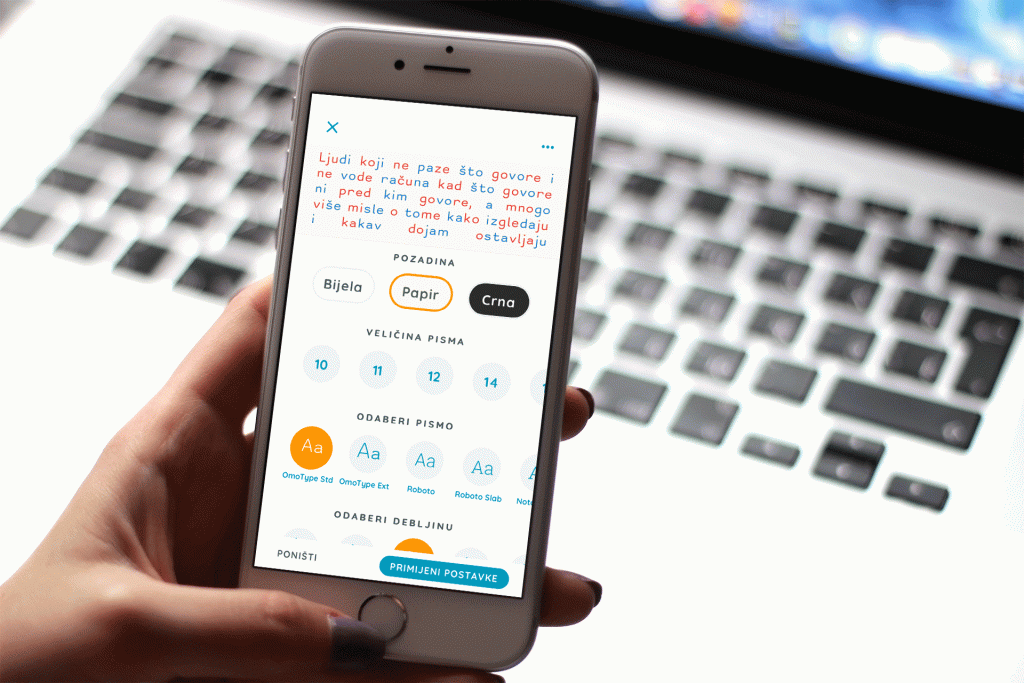
Their initial idea was to create an app with all the basic features of a book reader. Such as supporting a lot of different document formats, changing the font type and size, background colour, the space between letters, etc.
Features
The key feature we needed to integrate into the app was the option to separate words into syllables. So we started the R&D phase by searching for some kind of algorithm or a ruleset for separating the words.

Luckily after a month or two, we found a research paper named: “The automatic syllable separating process based on the principle of the highest access and the statistics of Croatian language syllables”. The authors were Ana Meštrović and Sanda Martinčić-Ipšić from the Department of Computer Science of the University of Rijeka and Mihaela Matešić from the Faculty of Philosophy of the University of Rijeka.
This paper covered all the rules and exceptions we needed for our algorithm and we were able to integrate it into our reader, giving users two colour contrast options for the separation. Along with separating syllables, we wanted to implement a moving line, acting as a finger or pen, marking the read text and adjusting the reading speed.
The “b and p” issue
Research on reading disorders has also shown that some people have issues mixing up letters p and b. So, we added a “mirrored letters” option in which the users can decide between 4 combinations of highlighting the edge of the “belly” of the letter or putting a dot in the “belly”.
Users currently have the option of importing books/files from their local storage/cloud into the app. You can also download books from the free online service provided by the Ministry of Education. The online service provides more than 200 books, mostly consisting of elementary and high school book assignments.
Registering and logging into the app is not required, however, users have the option of registering. All you need to leave is just the basic information and information about their reading disorder (if they have one). In return, they have the permission of using the .epub converter, which converts a wide variety of formats to .epub and the OCR (Optical Character Recognition). It scans any block of text and imports it into the Notes folder inside the app. We added these two features to the app so that users with reading disorders could import or scan everyday documents, newspapers, etc.
As well as gathering basic information about registered, the app also gathers information about the font types, sizes, weights, background colour, etc. It gives us the option to analyze which are the most commonly used preferences. We look at the development of the OmoReader app as a continuous process and we will constantly improve user experience in the app, so we could get the most optimised version of the product at the end.
Under the hood
Ionic was the app main framework, which enables developing hybrid mobile apps in web technologies, mainly HTML, CSS and Javascript (Angular 7). Besides the framework, an important part of the app had the base on the epub.js library, but we adjusted it to the needs of our app. We implemented OCR and format
At first, the app supported all available eBook formats, ePub, PDF,
Hyphenation
One of the most important features of the app, separating the syllables, was also one of the toughest problems to crack. In the beginning, the algorithm seemed to be an easy issue to solve (the first thought was just separating syllables at the vowel) but in the end, it turned out to be a lot harder. While researching, we realised we can’t define the rules for writing the algorithm by ourselves.
If you ask someone to disassemble a word into syllables, most people will answer correctly, but if you ask them what methods and rules they used, they probably wouldn’t know. Our task was to research all grammatical rules and figure out a way to implement them inside the app. Those are the kinds of questions you can’t just Google, but somehow we found the above-mentioned science paper, that was a perfect fit to solve most of our problems.
Getting ahold of an algorithm
We contacted the authors who let us use their algorithm which was in Python and wrote it in JavaScript. A functional algorithm was only the first step because we needed to find a way to
We needed to create an algorithm that can modify the HTML structure in books, so we could enable the colouring of syllables and marking mirrored letters. But still, we had to do it without ruining the design of the book and making it efficient and fast.
The grey line
Another feature we had problems implementing was the grey line which enables users to follow the text while reading. It helps them focus on the text. The line needed to have multiple reading speeds, so we had to give a lot of attention to calculating the duration of the line for each word. The reason was to secure that the line wouldn’t move too fast or too slow over that word.
Developing some of the features that we needed, completely from scratch, would have to take at least a couple of years. Thankfully, we found open source API-s, libraries and services which fit our needs, so we used it in the app. With complex tasks like this, it’s always better to use finished solutions, given that they fit your needs. You can modify it to do so, rather than to develop something from scratch. Especially if you’re on a fixed budget and deadline.
Try it yourself!
That’s about it, thanks for taking the time to read everything about our Omoreader endeavor.
In case you’d like to see what the fuss is all about, feel free to head over to Google Play or App Store, and find a new way of reading your favourite book titles!













