
A viral post suggested that language models like ChatGPT could pick the perfect watermelon just by looking at photos and listening to knocking sounds. No tapping, no guessing, no vintage family tricks – just upload an image or video and let the AI decide.
We couldn’t resist testing this idea.
Given the intriguing nature of this claim, we designed an experiment where humans and multiple AI models competed to choose the best melon from a batch of ten.
The rules were simple: both sides had to make their pick based only on what could be seen, heard, or felt on the outside, and then we put those predictions to the ultimate test, a blind taste challenge.
The objective
Can AI Really Choose the Best Watermelon?
Our experiment wasn’t only about testing whether AI can identify the best watermelon in a store, it was about examining how much we can trust AI with tasks that have always relied on human senses like sight, touch, and hearing.
- How do human predictions compare to AI-generated ones
- Does the watermelon that participants and AI models pick as the “best” align with those that actually score the highest in taste tests?
- What does this experiment teach us about AI’s ability to handle subjective assessments, like taste?
To get clear answers, we focused on the following core questions:
- Is the 1st choice made by humans or AI in the top 3 watermelons based on group ratings?
- Is the 1st choice in the top 3 individually-rated watermelons by taste?
- Conversely, is their 1st choice in the bottom 3 group-rated or individually-rated watermelons?
The Process: How We Set It Up
Step 1: Selecting the Watermelons
We kicked things off with 10 carefully chosen watermelons, selected for variety in size, shape, and appearance. But instead of numbering them like lab samples, we wanted something more entertaining. So, we turned to AI and let it christen our melons with names that made the experiment easier to follow, and a lot more fun.

Step 2: Gathering Data from Humans
Before anyone got a bite, we turned the watermelons into mini movie stars – snapping photos, recording videos, and even capturing the sound of the classic knock test. Then it was up to our team of eight to judge each melon with nothing more than their eyes, ears, and instincts.
On a scale from 1 to 10, they scored appearance, sound, and overall “feel.”
No tasting yet, this round was all about first impressions.

Step 3: The AI Involvement
To keep the comparison fair and engaging, we used more than one option. Multiple large language models were asked to predict which watermelon would taste the best just by using the visuals, knocking sounds, and physical details collected in step one.
This allowed us to compare not only human vs. AI judgment, but also how different models approached the same task.
Step 4: The Blind Taste Test
After the predictions were in, it was time to bring out the knives.
Toni cut a middle slice from every watermelon and secretly numbered the plates. Only he knew which melon was which, so the rest of the team went into the taste test blind.
Each participant then scored the samples on a 1–7 scale across sweetness, texture, juiciness, and aroma.
Sweetness
1 – No sweetness at all; bland or watery
2 – Barely noticeable sweetness
3 – Mild, underwhelming sweetness
4 – Medium sweetness; decent but not exciting
5 – Clearly sweet; pleasant and enjoyable
6 – Very sweet; strong and satisfying flavor
7 – Exceptionally sweet; rich, ripe, and delicious
Texture
1 – Very mushy, mealy, or unpleasant
2 – Soft and inconsistent; lacks firmness
3 – Slightly soft; acceptable but average
4 – Balanced; not mushy, not fully crisp
5 – Mostly firm; a nice, clean bite
6 – Crisp and satisfying to chew
7 – Perfect texture; snappy, firm, and fresh
Juiciness
1 – Dry; barely any juice
2 – Low juiciness; feels dehydrated
3 – Slightly juicy, but not enough
4 – Moderately juicy; expected for a watermelon
5 – Juicy and pleasant; starts to drip
6 – Very juicy; bursts with juice
7 – Extremely juicy; overflows with refreshing liquid
Aroma
1 – No aroma; neutral like water
2 – Very faint; barely noticeable
3 – Light scent; detectable but weak
4 – Moderate, clean watermelon aroma
5 – Clearly fruity and sweet-smelling
6 – Strong, fresh, and inviting scent
7 – Intense, rich, mouthwatering aroma
Once all the ratings were done, we tallied the points from every category – sweetness, texture, juiciness, and aroma.
The sum gave us a final group score, showing which melons stood out as crowd favorites and which ones didn’t impress.

Human Prediction Results: How Well Did We Pick?
We deliberately designed the experiment around a realistic scenario: you walk into a store and need to pick just one watermelon from a large pile. There’s no way to taste it in advance, so your choice has to rely entirely on what you can see, hear, or feel.
It’s the kind of decision most people make during a regular grocery trip. This context helped guide how we approached evaluating both human and AI predictions.
It’s also important to note that none of the participants in this test are professional watermelon evaluators. They don’t grow, harvest, or sell watermelons, nor do they have any formal training in fruit selection. They’re just regular people trying to pick a good-tasting watermelon based on what they’ve learned anecdotally, whether from family, social media, or gut feeling.
This makes the experiment more relatable and aligned with how most consumers make these decisions.
To evaluate how accurate human predictions were, we analyzed each participant’s first choice and compared it to the actual taste rankings. The goal was to determine whether participants could successfully identify the best-tasting watermelon using only pre-tasting cues: visual inspection, knocking sounds, weight, and gut feeling.
We used four criteria to evaluate each prediction:
- Was their first choice in the top 3 group-rated watermelons by taste?
- Was their first choice in their own top 3 watermelons by taste?
- Was their first choice in the bottom 3 group-rated watermelons by taste?
- Was their first choice in their own bottom 3 watermelons by taste?
To ensure fairness, we applied a ranking system that accounts for ties. When two or more watermelons had the same total taste score, they were assigned a shared rank by calculating the arithmetic mean of their positions. For example, if two watermelons were tied for second place, both were given a rank of 2.5.
This tie-aware ranking approach impacted how we determined the top and bottom 3 positions: if multiple watermelons shared a rank that fell within or at the edge of the top/bottom 3 range (e.g. two tied at 3.5), we included all of them. This meant that sometimes more than three watermelons were considered in the “top 3” or “bottom 3” evaluations. If two or more watermelons shared the same rank (e.g. tied for 3rd), they were all included in the top or bottom 3.
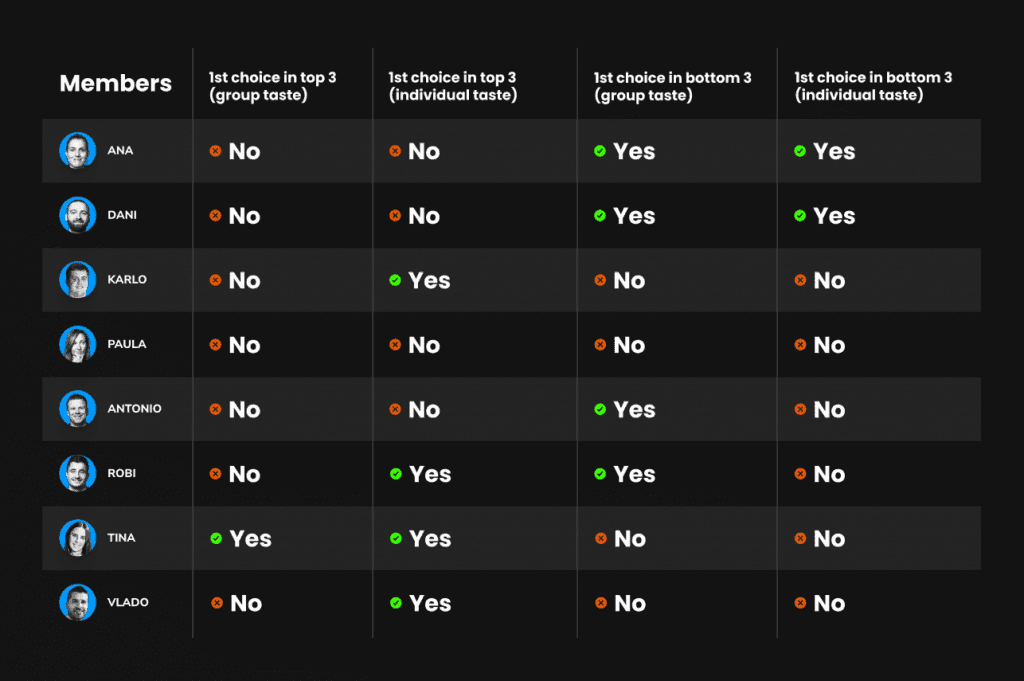
Notable Findings
- Ana E. picked Chunk Norris as her top choice, which ended up near the bottom in both the group and her individual rankings. A clear case of prediction misalignment.
- Dani also chose Chunk Norris first. It was rated 9th by the group and was among his three lowest individually which is a consistent but unfortunate mismatch.
- Karlo selected The Crimson Beast. While it didn’t make the group’s top 3, he personally rated it among his highest.
- Paula also chose The Crimson Beast. It landed right in the middle of the pack by group score and slightly lower in her own ratings, which means neutral overall.
- Peka went with Lil’ Zest, which the group rated among the worst, though it didn’t fall into his own bottom 3.
- Robi picked The Sweetinator, which placed 6th in the group average and 5th for him. Not a bad guess, but not top-tier either.
- Tina predicted The Sweetinator, and it performed well, landing in both her top 3 and the group’s top 3. A strong alignment.
- Vlado selected Rindalina as his top choice, which turned out to be his personal favorite in the taste test, though not ranked as highly by the group.
These results highlight just how nuanced and unpredictable sensory judgments can be when relying only on surface-level features. Most participants approached their choice logically, looking at shape, listening to the knock, or judging based on weight, but very few predictions aligned with overall group preferences.
This variability is exactly why we were interested in comparing these results with AI-generated predictions. Could AI models, trained on general knowledge and optimized reasoning, do any better in the same constrained, real-world conditions?
AI Prediction Results: How well did the AI pick?
To evaluate the predictive performance of language models (LLMs), we provided each AI with access to the same visuals and audio that human participants used: images of each watermelon from all sides and a short knocking video. No taste data or human ratings were revealed to the models.
We tested several configurations of modern LLMs and prompted them to rank all 10 watermelons. The full list of models included:
- Claude Sonnet 4 (images only)
- Gemini 2.5 Pro (images only)
- Gemini 2.5 Pro (images + knocking)
- Gemini 2.5 Pro (images + knocking + rolling)
- GPT-4.0 (images only)
- GPT-4.0 (images + knocking)
- GPT-4.0 (images + knocking + rolling)
Due to technical limitations, Claude Sonnet 4 could only analyse static images, while Gemini 2.5 Pro and GPT 4.0 had access to multiple input types: visual analysis, knocking audio, and rolling video footage. This multi-modal approach allowed them to replicate the full sensory experience humans use when selecting watermelons in stores.
We provided each AI with identical media and asked them to rank all 10 watermelons from best to worst, including their reasoning for each placement. Importantly, we gave no guidance on evaluation criteria – yet, all AI models converged on the same traditional parameters humans have used for generations: surface patterns, shape symmetry, knocking sound quality, stem condition, field spot appearance, and overall visual appeal.
The table below shows how each model ranked our 10 watermelons:

After testing all possible input combinations, we selected each model’s best-performing version for our final comparison:
- Claude Sonnet 4: Images only (baseline capability)
- Gemini 2.5 Pro: Images + knocking audio
- GPT 4.0: Images + knocking audio
Interestingly, adding knocking sounds consistently improved prediction accuracy across models, while rolling video footage actually degraded performance—suggesting that motion may introduce visual noise that confuses the AI’s pattern recognition systems.
The main evaluation focused on one question: how well does an AI’s top-ranked watermelon match with actual taste results? For each AI model, we looked at:
- Is its first choice in the top 3 group-rated watermelons?
- Is its first choice in the bottom 3 group-rated watermelons

In short: Claude and Gemini models played it safe with mid-tier melons, while GPT-4.0 often gambled and ended up choosing some of the worst performers.
Claude Sonnet 4 (images only) picked Crunchcore, which landed mid-table (rank 6.0). Gemini 2.5 Pro, whether using images, knocking, or rolling, consistently chose The Crimson Beast, a safe but unremarkable middle pick. GPT-4.0 was riskier: one version went for Chunk Norris (bottom 3, rank 9.0), another chose Juicy McCrack (also in the bottom 3 band, rank 7.5), and a third picked Lil’ Zest (again bottom 3, rank 7.5).
None of the LLMs selected a watermelon that made it into the top 3 group-rated watermelons. However, GPT-4.0 (images only), GPT-4.0 (images + knocking), and GPT-4.0 (images + knocking + rolling) each selected a watermelon that landed in the bottom 3.
We also checked which LLM overlapped the most with each participant’s individual top 3 tasting results. This allowed us to measure how well each AI aligned with personal preferences and not just the group average.
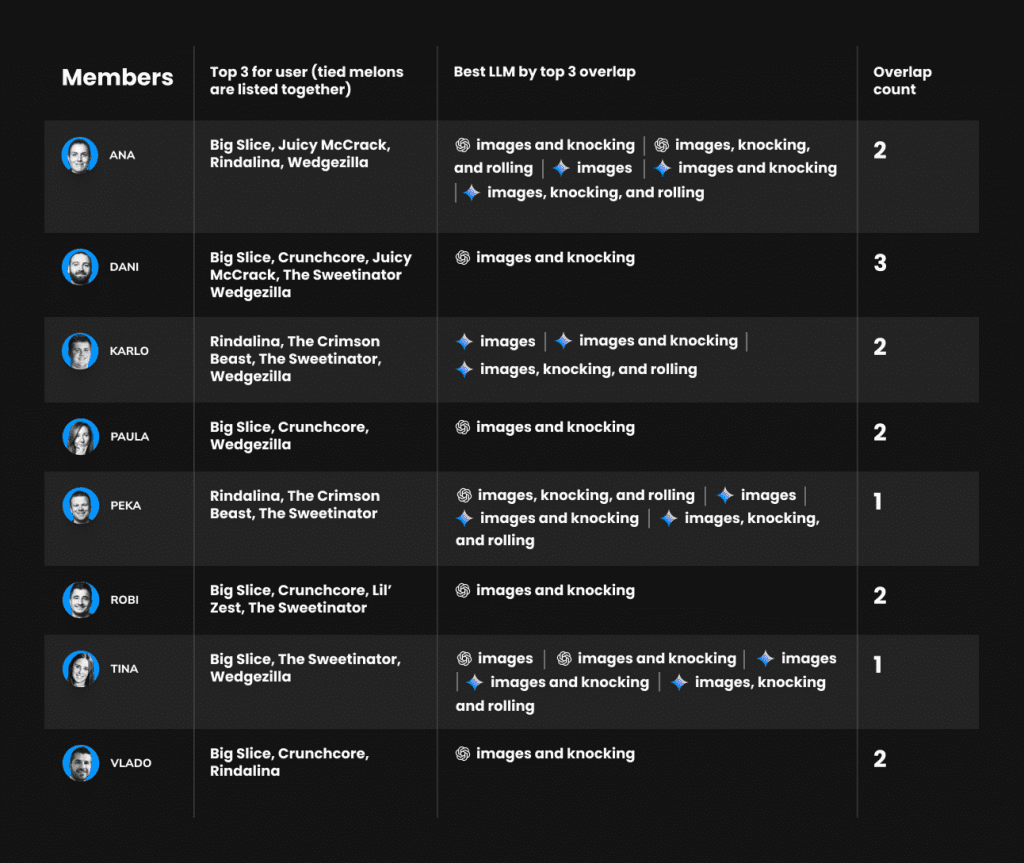
- Dani had the strongest alignment with GPT-4.0 (images + knocking) where it matched all three of his top-rated melons.
- Tina, Karlo, and Ana E. also showed relatively strong alignment, with multiple models achieving 2/3 matches with their individual taste rankings.
- Peka was the toughest user to match because no model overlapped with more than one of his personal top 3
- GPT-4.0 (images + knocking) was the most consistent performer, showing overlap with multiple participants.
- Gemini 2.5 Pro (images + knocking) and GPT-4.0 (images only) followed closely behind, with solid overlap results.
- Claude Sonnet 4 (images only) had limited alignment with no overlaps
The boundaries of our experiment
It’s important to recognize the limitations of this whole process.
First, our approach relied on general-purpose LLMs rather than AI tools specifically designed for fruit evaluation. This likely influenced performance, since these models lack the specialized knowledge a dedicated fruit-picking system might offer.
Second, our human participants were everyday consumers and watermelon enthusiasts, not professional tasters or buyers. Involving experts could have provided a stronger benchmark for comparison.
Finally, while we tested several LLM setups, exploring a wider range of models and prompting methods might reveal more about AI’s ability to handle subjective tasks. And although higher-quality recordings could have improved results, we chose to rely on standard smartphone photos, videos, and audio to better reflect a real-world shopping scenario.
AI vs Human Conclusion – A Sweet Tie
This experiment began with a simple premise: could AI help you pick a better watermelon than your own skills and intuition? Well, not exactly. None of the AI models managed to pick a watermelon that ranked in the group’s top three by taste. In fact, several landed squarely in the bottom three, especially when more sensory input (like knocking and rolling) was added.
The picture changes somewhat when we shift from collective preference to individual alignment. Some models matched personal taste profiles a bit better. One model (GPT-4.0 with images and knocking) achieved a perfect match with a participant’s (Dani) top three best rated watermelons. Several others hit two out of three.
Humans didn’t exactly shine in this test either. Most participants missed the mark when it came to selecting the group’s favorite melon. Only one participant (Tina) successfully aligned with both the group’s top picks and their own individual favorites, and one participant (Vlado) managed to pick out his favourite tasting watermelon but his taste was quite different from the groups. The rest had mixed results, often picking watermelons that performed poorly by taste but had visually appealing traits.
If you take into account our scenario, where you’re about to pick one watermelon to take home from the store both humans and AI failed miserably:
- The best rated watermelon (Big Slice) was ranked as worst for 4 out of 7 AI configurations. The other 3 rankings were 8th, 5th and 3rd place.
- Human group prediction also had Big Slice as the worst ranked watermelon
- If you went by first pick, the best possible rated watermelon you could get was Crunchcore (Gemini 2.5 pro with images) which placed 5th in the group ranking.
Interestingly, the highest-rated watermelon by taste (Big Slice) defied almost every traditional heuristic we thought we knew. It was oversized compared to the others, had a very pale yellow spot, and the overall green color was light and dull. When we knocked on it, the sound didn’t resonate convincingly, and slicing it open revealed a pale, watery-looking red interior.
All signs pointed to disappointment. And yet, once we took a bite, Big Slice turned out to be the undisputed star: sweet, juicy, and bursting with flavor. It served as a humble reminder that our visual cues can be deeply misleading.
So the next time you’re staring at a stack of melons, wondering if the shiny skin or golden field spot will lead you to the sweetest bite, remember this experiment.
You can knock, you can ask an AI, or you can just trust your gut – but none of these methods are perfect.
The sweetest melon might be the one that looks the least promising and surely you have already learned that in fruit, as in life – appearance can be deceiving.





